
Czasami coś nie działa i przyczyna tego za diabła nie chce dać się znaleźć. Poniżej kilka pomocnych rad w debugowaniu w środowisku chmury i kontenerów, czyli “u mnie działa, a na cudzym komputerze nie”
Problem
Moja strona nie działa, a devops skomplikował sprawę. Na wejściu do naszego serwisu stoi ELB, ALB lub inny load balancer, który przekierowuje ruch do kontenera zarządzanego przez ECS lub kubernetes. Żeby było trudniej, nie mamy dostępu do czeluści load balancera i wejście na noda klastra też jest ograniczone. Możemy jedynie dostać się do kontenera.
Porblem pojawia się gdy frontend (UI) wysyła żądanie do backendu. Nie dostajemy poprawnej odpowiedzi, a jedynie błąd 503 Service Unavailable.
Rozwiązanie
Znajdź problem i napraw 🙂
Rozwiązanie 2
Zanim zaczniesz grzebać, upewnij się, że zepsucie danego kontenera nie pociągnie za sobą negatywnych konsekwencji. W przypadku Kubernetesa, ECS lub innych orchestratorów (jakkolwiek to się tłumaczy) usunięcie zepsutego kontenera powinno spowodować automatyczne utworzenie nowego, takiego samego. Oprócz tego dobrą rzeczą będzie kawałek papieru lub gedit do notowania co robimy, aby łatwo dało się zrobić rollback zmian, które są trwałe lub odtworzyć całą ścieżkę.
Ponadto pomyśl czy żądanie/request, które będziemy naprawiać nie niszczy czegoś po stronie backendu. Jeśli problem sprawia guzik “skasuj konto” to dwukrotne debugowanie tego samego requestu będzie problematyczne…
Sprawdź co nie bangla
Na początek znajdź z użyciem developer tools jakie żądanie sprawia problem. Otwórz developer tools w przeglądarce i popatrz co się dzieje gdy strona wysyła do backendu request. W dalszej części bardzo pomocne będzie skopiowanie polecenia cURL z dokładnymi parametrami żądania, które wysyła przeglądarka. W zakładce z listą połączeń sieciowych z developer tools możesz wybrać skopiowanie requestu m.in. jako polecenie programu cURL.
Ponadto, w ulubionym edytorze tekstu, jakim jest oczywiście pico albo gedit, zapisz powyższe polecenie. Często bedzie ono zawierało całą masę nagłówków, id sesji, ciasteczek i innych rzeczy, które weryfikuje backend w celu uwierzytelnienia człowieka. Jako użyteczny dodatek możesz zamienić w takim poleceniu nagłówek User Agent na własny string. W większości logów user agent pojawia się w każdej linijce logowanego requestu i dzięki temu będzie nam łatwiej przeszukać logi tylko z naszego curla.
Mając powyższe sprawdź czy curl dostaje tak samo niepoprawną odpowiedź od serwera. Możliwe że już na tym etapie otrzymasz komunikat z błędem i dalsze debugowanie stanie się zbędne.
Logi
Chyba podstawowa rzecz, dużo grepa, a jeśli to AWS to dużo scrollowania i szukania w cloudwatch. Jeśli nie ma w logach aplikacji z backendu, to możliwe że jest w logach load balancera. Jeśli nie, to…
Czas na grubszy kaliber
Czasami błąd jest tak uciążliwy, że ani w logach ani w odpowiedzi backendu nie da się znaleźć jego przyczyny. Pozostaje więc kilka cięższych dział:
Wewnątrz kontenera – netstat
Odpal netstat z pakietu net-tools w Ubuntu/Debianie. Polecenie netstat -ntap powinno wypisać wszystkie nawiązane połączenia i otwarte porty. Sprawdź czy wszystko jest tak jak powinno, tj. czy serwer nasłuchuje na odpowiednim porcie, czy widać połączenie z bazą etc.
Jeśli wszystko jest ok, to spróbuj wykonać to samo podczas wykonywania żądania przez cURL. Jeśli takie żądanie wykonuje się za szybko i nie nadążasz klikać, to wrzuć gdzieś sleep 10, tylko nie zapomnij go usunąć 🙂 Ponieważ często po zmodyfikowaniu kodu potrzebny jest restart serwisu, a ubicie głównego procesu spowoduje restart kontenera, spróbuj kill -HUP [proces]. Dawno dawno temu, gdy komputery obsługiwało się bez myszki (i nie przez touch screen) zdarzało się, że coś zerwało połączenie z terminalem, na którym mieliśmy uruchomiony interaktywny proces. Przez SIGHUP można było poinformować taką odłączoną aplikacje, że straciliśmy z nią połączenie i chcemy aby się zakończyła. Serwery zwykle nie reagowały na to, jednak przez lata SIGHUP stał się sygnałem do reloadu konfiguracji i często również skryptów, które są wykonywane przez serwer. Dzięki temu prawdopodobnie nie zrestartujesz kontenera, w którym pracujesz.
Wracając do tematu – mając już wrzuconego gdzieś sleep 10 spróbuj netstat ponownie i zobacz czy nic nie wygląda podejrzanie
cURL do kontenera
Kolejnym punktem do odhaczenia jest wysłanie żądania przez cURL bezpośrenio z kontenera do niego samego. Możemy wykorzystać wcześniejsze polecenie cURL. Możemy też dodać opcje wymuszającą na cURL’u wyświetlenie nagłówków. Jeśli się powiedzie, to problem prawdopodobnie pojawia się gdzieś wcześniej, np. między load balancerem a kontenerem. Jeśli masz taką możliwość, wykonaj to samo z load balancera.
nc do innych usług
Jeśli to zadziała, dobrze jest sprawdzić połączenie z bazą lub innymi wymaganymi serwisami bezpośrednio z kontenera: nc nazwa_hosta port ( apt install netcat). W przypadku bazy można doinstalować jej klienta i spróbować się połączyć, przy okazji wykonując jakiś prosty select na tabelach, do których aplikacja ma mieć dostęp.
Udawanie innych serwisów
Kolejnym trikiem, który może się przydać jest odpalenie czegoś, co udaje bazę lub inny serwis. Pozwoli to poznać nam jakie żądania są wysyłane do sąsiednich usług. Może to być przydatne gdy nie mamy możliwości zainstalowania tcpdump lub jest to zabronione.
Jak to zrobić aby stało się to tylko lokalnie, bez psucia całej infrastruktury? Sprawdź jaki host jest ustawiony jako np. mikroserwis, który chcesz podsłuchać (jeśli używasz po IP, to sorry…). Następnie wpisz w /etc/hosts nowy wpis: 127.0.0.1 [nazwa hosta] i odpal w kontenerze nc -l [port usługi]. W Linuksie pierwszeństwo w ustalaniu adresów przypisanych do hostów ma plik /etc/hosts, dzięki czemu dodając do niego nowy wpis wymusimy aby nasz kontener połączył się z localhost zamiast właściwego hosta. Uruchomiony program nc pozwoli wypisać to, co miało zostać wysłane przez aplikację z naszego kontenera do serwisu. Pamiętaj, aby usunąć później wpis z /etc/hosts 🙂
Podglądnięcie zmiennych środowiskowych
Często zanim połączymy się z bazą lub podglądniemy ruch sieciowy do danego hosta warto sprawdzić jakie zmienne znają aplikacje, które są już uruchomione w kontenerze. Czasami przez błąd w konfiguracji aplikacja może nie mieć możliwości uzyskania tych zmiennych, bo np. zabrakło uprawnienia IAM do odpytania Secret Parameter Store. Może też to wynikać ze zmienionego API lub biblioteki – zamiast jednego requestu o listę wszystkich parametrów odpytuje o każdy z osobna, do czego IAM już nie uprawnia.
Wykonaj ps aux. Zwykle pierwszy proces będzie znał tylko te parametry, które są przekazywane bezpośrednio przez dockera. Wszelkie inne, uzyskiwane z chmury są znane późniejszym procesom, po pełnej inicjalizacji środowiska. Możesz podglądnąć jeden z wyższych PID’ów (ale nie z naszej sesji!) przez wpis w /proc/[pid]/environ:
sudo cat /proc/123/environ | tr ‘\0’ ‘\n’
Poszczególne zmienne są rozdzielone zerami (znakami o kodzie zero), stąd tr, który zmieni zera na nowe linie. Jeśli wygląda ok, to pijemy kolejną kawę i szukamy dalej
Ponownie netstat, lsof
Sprawdź ulimit i porównaj z ilością połączeń i otwartych plików w kontenerze. W zależności od konfiguracji ten parametr przy dużej ilości połączeń może stwarzać problemy
Podglądanie z czym się łączy aplikacja
Sprawdzisz to przez tcpdump udp port 53. W trakcie działania sniffera możesz wykonać żądanie przez cURL i sprawdzić co się dzieje i z czym się łączy aplikacja. Jeśli używasz IP, to zapytanie tcpdump będzie trochę inne.
strace do czytania logów
Jeśli cloudwatch szczególnie uwiera tu i ówdzie, przez co nie możesz znaleźć logów, warto sprawdzić co aplikacja wypisuje na standardowe wyjście. Nightmare w kontenerze? Nie 🙂 Spróbuj:
strace –attach=[pid serwera] -e write=1,2
Powyższe podłączy “debuger” strace do procesu i będzie wyłapywało jedynie wywołania systemowe funkcji write do plików o fd=1 i 2. Oznaczają one odpowiednio stdout i stderr.
Nie jest to najwygodniejsza metoda oglądania logów, ale pozwala użyć ukochanego grepa i awk’a, co w przypadku cloudwatch nie zawsze jest najwygodniejsze i najszybsze.
Dla przykładowego ls wykonanego przez ssh:

otrzymamy wynik ze strace:
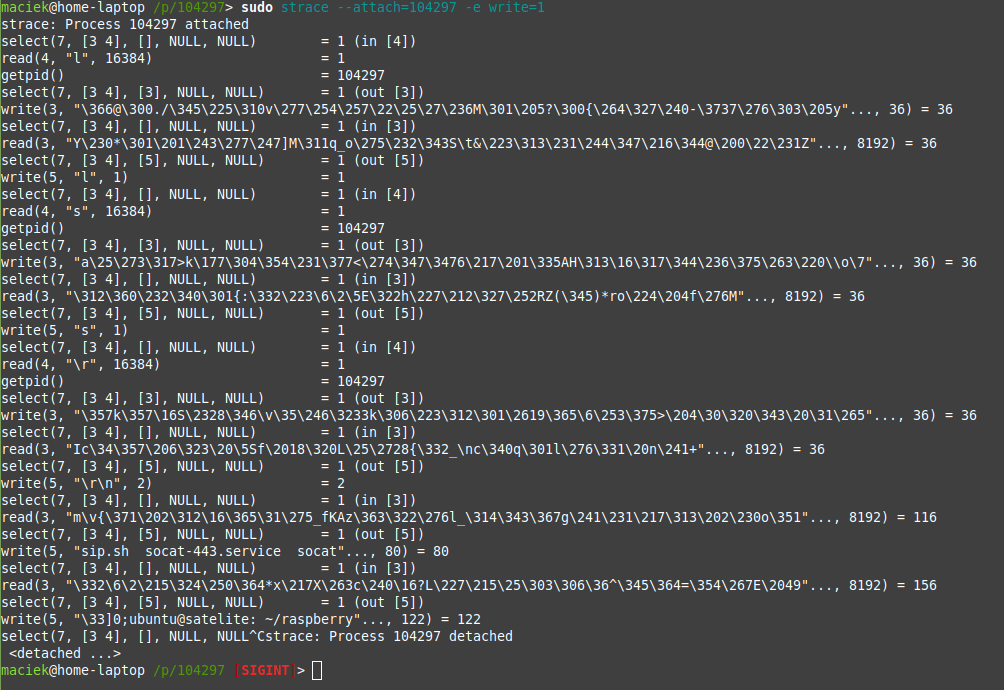
Nie jest to najczytelniejsze, ale odpowiednio okraszając to grep’em i wycinając wszystkie znaki sterowania terminalem (kolory, znaki specjalne etc.) możemy uzyskać dość czytelny wgląd w to, co się dzieje. Powyższa metoda zadziała też na połączeniach sieciowych, w tym na tych, któ©e są już odszyfrowane i idą np. do fcgi po systemowym sockecie.
Na koniec
Jeśli nie udało się nic znaleźć, a aplikacja dalej się sypie, to pozostaje stara dobra metoda… wyłącz i włącz kontener, później instancje, a na koniec pogadaj z frontendowcami i backendowcami którzy muszą wysyłać to problematyczne żądanie. Chociaż pogadać i zrozumieć jest dobrze przed całym powyższym szukaniem dziury w całym 😉